Jump To

Overview
The modern data stack continues to attract companies who are looking for a quick onramp into the world of cloud-based analytics and/or actively modernizing their legacy data stacks. We've enumerated the benefits of the modern data stack in previous articles.
One reality that many companies face when adopting cloud technology: designing data infrastructure for business in a cloud computing environment is just different. Legacy stacks can indeed suffice for many companies. But as business requirements grow and use cases increase, both in number and complexity, the models and assumptions that worked well enough in the data center become problematic. For one, they struggle at best to match the efficiency and scale that is possible on a cloud platform. Additionally, they force data teams to trade off subpar workflows to keep their antiquated technology in play.
The modern data stack helps these teams reimagine their data pipelines, not just hack their way forward. Consider what happens when a data analytics team hands off its work to a team of machine learning specialists. For most companies, this process is passively driven by what their legacy technology can support, and it is often inadequate for the use cases we see emerging and evolving today.
At Continual, we see the modern data stack as a path forward. It is simpler and helps clarify and illuminate the handoff between data teams. In this article, we will present a methodology for bridging the gap between data analytics and machine learning, aimed at helping customers accelerate their AI adoption.

Pitfalls of the Past: Why We've Failed
Data science and machine learning are not new, but there is plenty of evidence to show these practices have become quite cumbersome for many companies. By deconstructing their systems and identifying obstacles to productivity, we can learn how to build better data processes.
Pitfall 1: Data Teams Become Siloed
Early companies adopting the modern data stack often do not focus on specializations within the data team. This is a key difference when compared to enterprise companies. The modern data stack has grown up through small data teams of early adopters, unlike enterprises with dozens, if not hundreds, of data professionals. While any team lead might wish for those resources, small teams have to be creative, take on multiple roles, and focus on quick results.
An already-large IT organization could simply add a data team to complement a new objective, but it usually must do so with large-scale practices in mind. A new team is naturally segmented by role – data engineers, data analysts, data scientists – to prepare for additional hiring. These professionals get pigeonholed into their roles – with separation of concerns or avoiding duplication of effort in mind – and often don't interact outside of it. This is the beginning of a silo. As a result, few individual contributors worry about the "big picture." Strategic decisions are made mainly by managers focused on getting resources, interacting with governance, and reporting at some regular cadence.
In smaller modern data teams it is quite common to hear "everyone does everything." Recently, I was chatting with a client who reminded me, "We don't have the luxury of throwing stuff over the fence or waiting around for things to be delivered to us. If you want something done, you have to do it yourself."
Pitfall 2: Data Teams Create their Own (Siloed) Data Processes & Tooling
As specialized groups within a large data team develop, they inevitably craft
their own internal processes and select tools they know. And why not? A data
analyst’s day-to-day experience is very different from a data
engineer’s. Proper tooling often means greater productivity to its
users.
At the same time, specialized tool selection can also lead
to little or no emphasis on building a coherent, end-to-end data workflow.
Each team may have a solid process for their scope of practice, but what about
the handoffs they must negotiate? Do these tools and processes aid inter-team
collaboration?
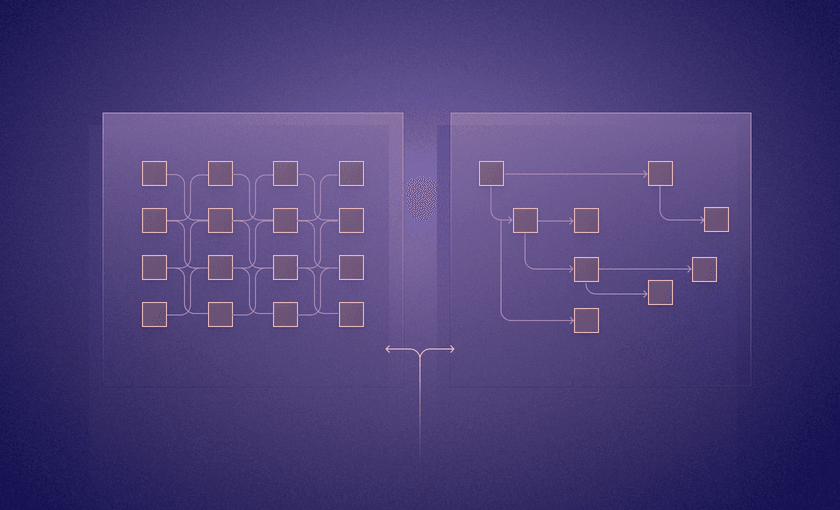
A common result is what we call pipeline jungles. We’ve all seen them: architectural or process diagrams that contain dozens of nodes, and maybe hundreds of connections. Does any one person understand the entire system, front to back? Probably not. Let the finger-pointing begin!

Each data workflow becomes its own undertaking to build, maintain, and debug. Specialized data teams can quickly get so consumed by glue code and task management that an entirely different team – one focused on DevOps, for example – comes in to manage those tasks. The most likely answer to all this complexity is some kind of orchestration tool.
Orchestration tools may make managing complex pipelines easier for DevOps or other engineering teams, but they don't actually address gaps or fissures in the underlying data process. Is there a more straightforward approach that data teams can adopt to define and build robust data workflows?
It’s also important to remember the end consumer of all the data work. The data team mainly concerns itself with the data system. It usually does not feel the full force of missed SLAs, incorrect insights, use cases gone asunder, etc. And it’s not uncommon for business-oriented teams to be accordingly skeptical or untrusting of the data team. I believe a lot of this wariness stems from ineffective data processes that build up a history of data being unreliable. By streamlining the product and improving the reliability of the data team, businesses can learn to love and engage with data like they never have before.
Pitfall 3: Operationalization of ML Workflows is Extremely Challenging
One does not need to stretch the imagination to see how pitfalls 1 and 2 nicely cascade into a situation where moving an ML workflow into production is an onerous task.
In the best of scenarios, a company may be able to develop a process whereby several months of manual effort is required to move a workflow into production, at which point it can somewhat reliably be maintained. This typically relies on a cornucopia of MLOps tools, an abundance of glue code, and some high-skilled ML engineers or ML-savvy DevOps engineers, but it’s certainly possible for high-skilled companies. Lower skilled companies will often face the insurmountable complexity of operationalizing their work and also maintaining it.
Although there is no shortage of ML tools to help with any particular piece of the ML workflow, most of it has proven to be ineffective. As Sarah Catanzaro wisely put it: “[ML] tools are crap … They were not built with developer ergonomics in mind.” What the ML ecosystem greatly lacks is tooling that is opinionated about how production ML should be done. Tools strive to be as appealing and flexible as possible, but this creates an ecosystem of tools with one-off functionality and no well-trodden path to the operationalization of ML use cases. Workflow complexity is thus passed onto users, who are drowning in technical debt.
There has to be a better way.
A Way Forward
What we find in the above analysis is that many enterprise companies have segmented teams that are prone to selecting disparate data tools and processes that lead to complex pipeline jungles and negatively affect getting results back to the business.
Isn’t the simple solution just to erase the boundaries between teams? Well, no. There are non-trivial differences between data disciplines, and it’s not realistic to expect everyone to be a “unicorn” data professional. Instead, we should focus on designing data processes to adopt best practices, aligning our data teams on this process, and selecting tools that maximize the efficiency therein. If we succeed at this task, we’ll see that we’ve also reduced the barrier to executing ML use cases and have effectively bridged the gap between analytics and machine learning.
Below, we’ll lay out a methodology for constructing such a system.
Step 1: Align the Data Team on a Production Process
It may seem counterintuitive to start by fleshing out the end result and working backward, but I think this is critical to the long-term success of the data team. If a data team never rallies behind a coherent production process, it’s likely that most use cases are going to be dead on arrival as they won’t be resilient enough to handle the bumps in the road that any use case inevitably experiences after making it into production. Without alignment on a production process, things will often start to fall apart before the use case ever graduates from development into higher environments. Starting at the end of the road also ensures that the business is properly bought in to utilize the results of the use case as well.
In a previous article, we riffed on the benefits of taking cues from software engineering best practices when building out the data science team. In reality, it’s not just the data science team that should internalize and build upon these tips, but the entire data team. If the entire team is not aligned, we begin to fall into the pitfalls of the past and end up in pipeline jungle territory. There’s not only one approach that works here, but successful data teams are often taking a git-centric approach to data where production environments are automated by CI/CD systems and the focus is on establishing a declarative system where everything is versioned and easily tracked and maintained. Development work can be (and likely will be) messy and complicated, but the production process should be such that all rough edges are smoothed out before getting there, and it’s a pleasantly humdrum series of automated steps before the final result is derived. We think this approach, as also championed by dbt, should be core to a company’s data process.
And, to reiterate: this must apply to all teams. Simon Späti recently penned an excellent article that covers recent trends in data orchestration, including the shift to declarative pipelines, which includes the last mile of the data orchestrator itself being declarative. However, this approach is only really optimized if all the steps in the pipeline are declarative. Injecting non-optimal steps in the data process is a recipe for disaster, as a data workflow is only as good as its weakest link. For example, there are many ways in which we can bridge the gap between analytics and machine learning, but many of those rely on ad-hoc processes that will fall apart under the pressure of production, like jupyter notebooks and arbitrary python scripts. In my career, I’ve seen many companies fashion a stellar plan with regard to data engineering and analysis, but then struggle with machine learning because data scientists fall back on imprecise processes that aren’t suitable for production. The handoff between analytics and machine learning is often fraught with danger precisely because the workflow has not been holistically conceived.

Lastly, there has been much discussion in the past couple of years about data as a product or data teams as product teams, and anyone believing that proposition must surely see this as a corollary. It would be rather ludicrous to design products with little regard to how separate components communicated, integrated, and delivered results – and, likewise, it is exactly the same for a data team. By aligning data teams onto a unified production process, we enable smooth delivery of results and set up the team – and the business – for success.
Step 2: Align the Data Team on Tooling
Now that we have established our production process, the next step is to align the data team on tooling. This does not mean that every team must use the same tooling, but, rather, that every team should leverage tooling that aligns with our now-defined data process.
This is easier said than done. Every different tool utilized in the data pipeline represents a risk. The goal should be to minimize risks while still giving each team a nice, self-contained workflow and covering the entirety of the data process. Does the team need five different data transformation tools? Probably not – one will probably suffice. There are many, many tools out there from which to select – both open source and commercial – and it is possible to build a stack using many different combinations of technologies. There is no one correct combination of tools, but we generally advise the following:
- Align all teams on the same data platform. This might sound obvious, but having different platforms for different groups on a data team is going to make any kind of production process multiple times more challenging right out of the gates. It’s important to align everyone on the same platform to get the smoothest transitions between teams. You may break some hearts in the process, but it’s well worth the uptick in productivity as a result.
- Avoid tools that do not fit into your production process. These will likely add complexity and technical debt as users leverage them for use cases.
- Avoid tools that don’t align on your company’s methodology. For example, if your company has adopted a git-centric approach to data where production environments are automated by CI/CD systems via a declarative system where everything is versioned, avoid tools that: a) don’t integrate well with git, b) are not declarative, c) don’t mesh with CI/CD systems, d) are not automated, or e) don’t version assets well.
- Avoid tools with clumsy integrations. Building your own integrations is very 2010s and keeping up with current versions is a nightmare.
- Avoid tools that overlap. For example: leveraging an ELT tool for data transformations and an ML platform that includes a data prep tool is less ideal than an ELT tool and an ML platform without a data prep tool. “But isn’t more always better?” Not always. Tools that overlap are often going to be a little (or a lot) contentious with each other and have weaker integrations than those that have clear boundaries. Users pay the difference. Plus, having multiple ways to do something just creates additional inconsistencies in your data processes.
- For modern data stack customers, avoid tools not aligned with the modern data stack. One of the great benefits of adopting the modern data stack is the crazy synergy obtained by each subsequent addition to the stack. Diverting from the well-known path will likely result in negative consequences.
In terms of ML tools, we’ve previously covered the evolution of the ML platform in-depth, and we believe anyone building ML use cases for production needs to leverage a third-generation platform built for operational AI. In particular, the platform needs to contain the following:
- Collaborative Feature Store
- Declarative AI Engine
- Continual MLOps
Luckily, we’re building such a platform at Continual!
Step 3: Sanity Check the Development to Production Workflow
After we’ve ironed out the production process and selected our technology stack, we can now worry about how we move completed development work into production.
This should hopefully just fall into place if steps 1 and 2 above are executed well. If we’ve adopted a git-centric approach to data where production environments are automated by CI/CD systems via a declarative system where everything is versioned, then this step is likely as easy as constructing the declarative input and creating a pull request with the changes to production. And we’re done.
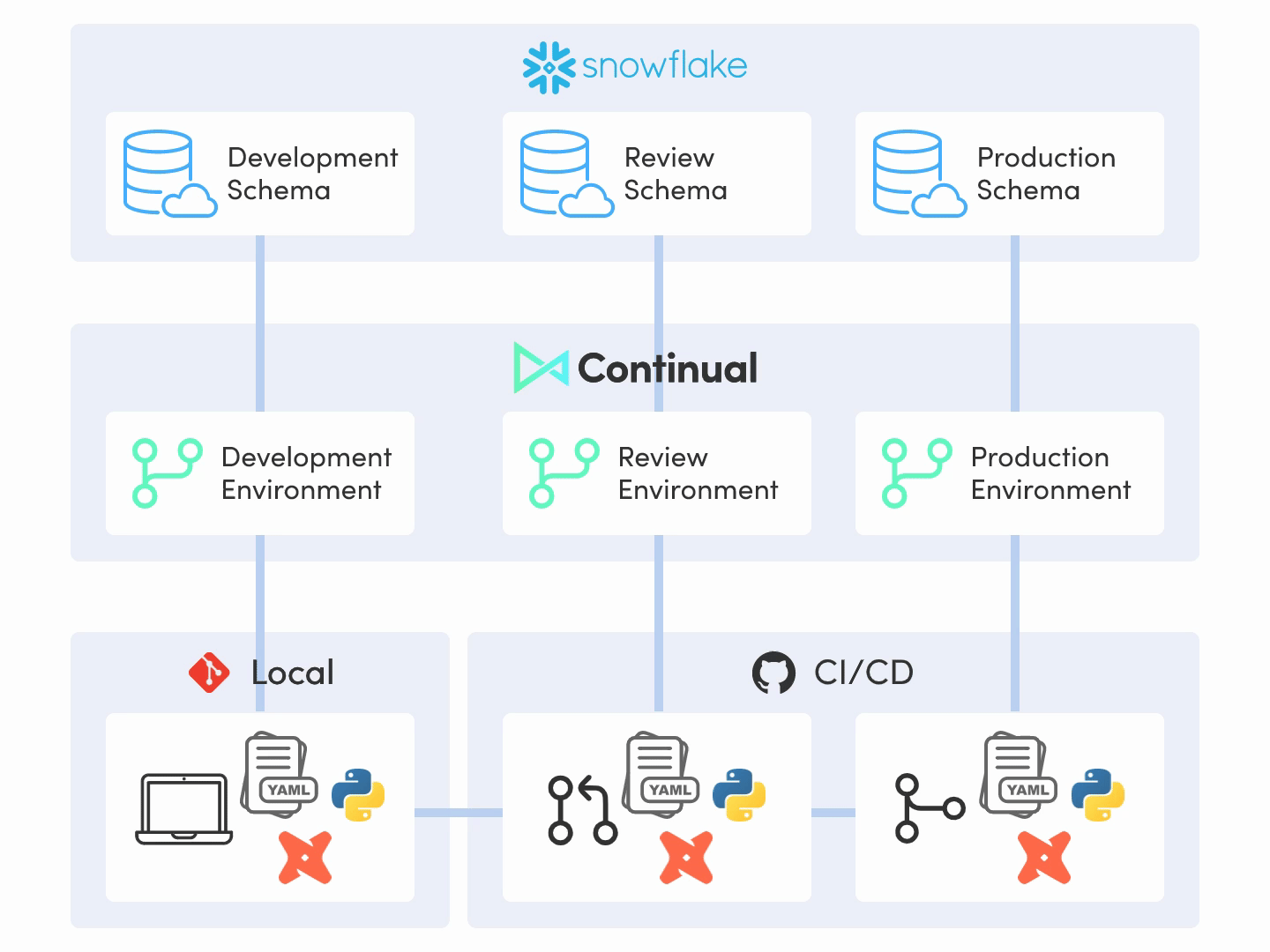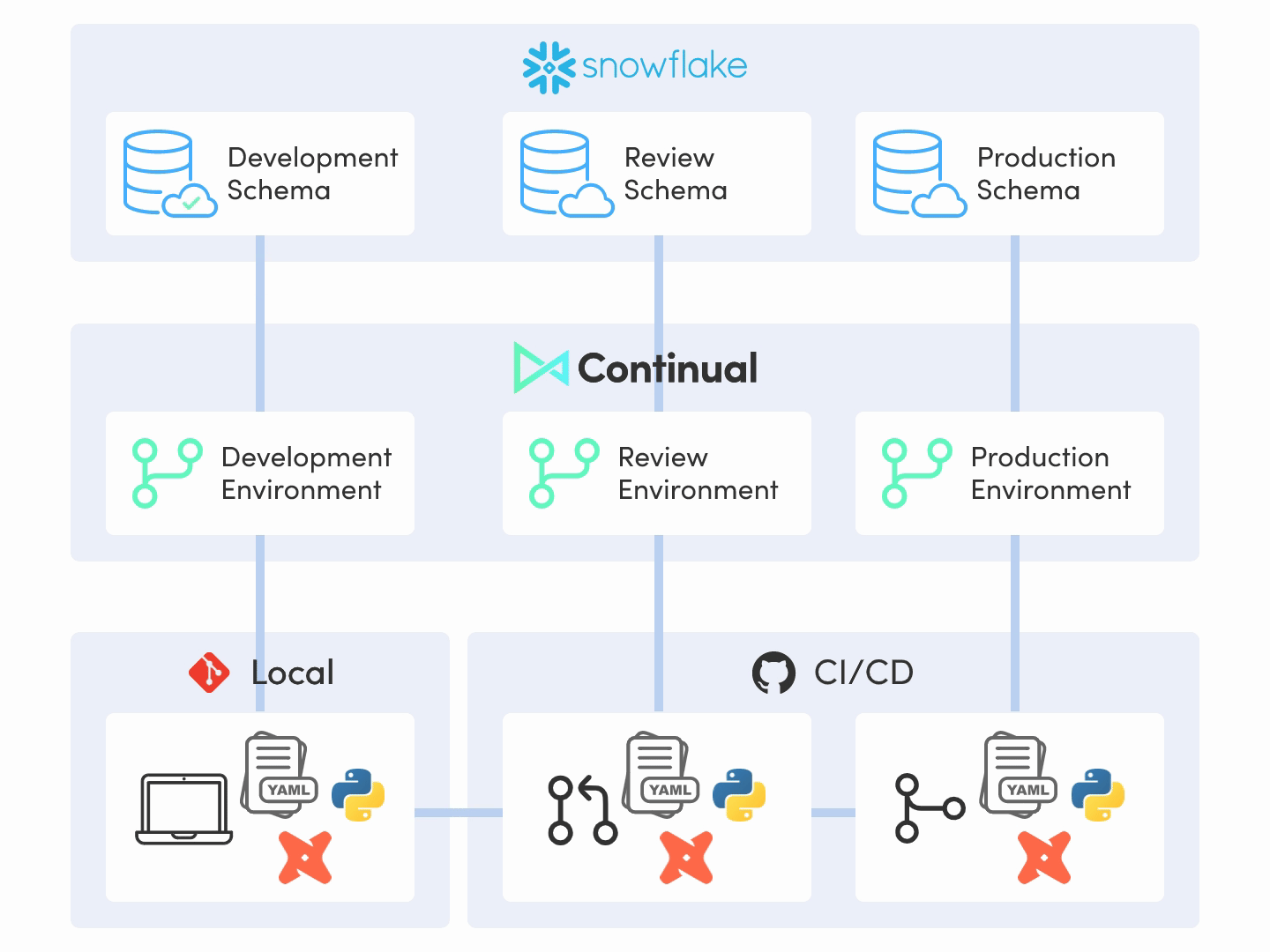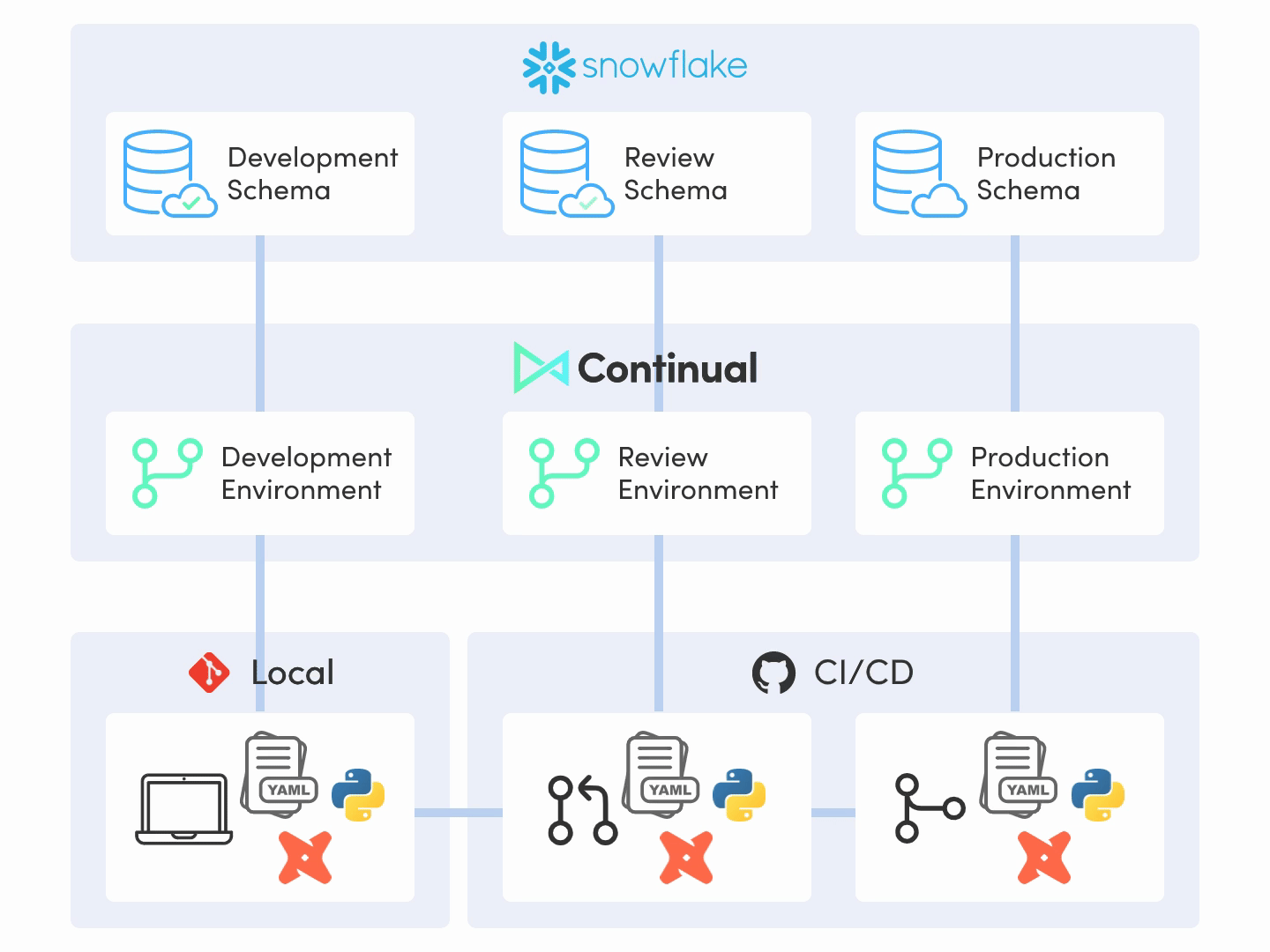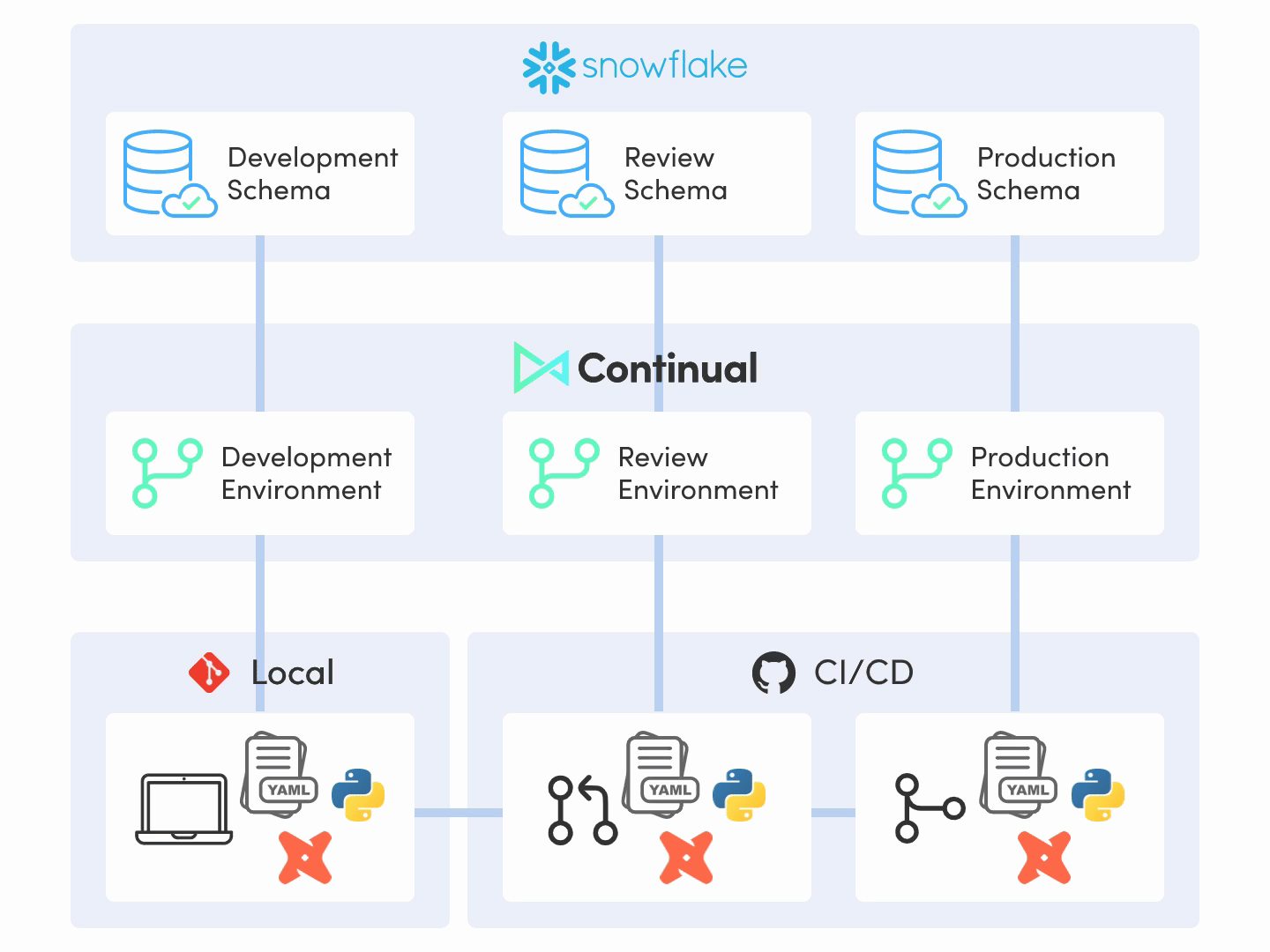
If this is not the case, then something has gone awry and we should revisit our thinking behind our production process and our tooling choices, as we’ve designed something that is more complicated than it needs to be. This is a good sanity check to determine if the system we’re building is well-designed: it should be extremely simple to operationalize one’s work.
Be forewarned that many ML tools are not geared towards this workflow and are instead focused on development use cases. Data science grew out of the research field, which is never heavily focused on operationalizing results, and the result is that many ML tools are similarly focused on notebook-based ML workflows. There is undoubtedly a place for notebooks for the data scientist (see the next section), but it’s crucial for operational tools to be built from day one with concepts like versioning, environments, automation, etc. Do not be re-invent the wheel here. If this process involves things like gluing together APIs and building bespoke pipelines from notebooks, keep searching.
Step 4: Let Builders Build
The last step here is to “let builders build” – i.e. empower advanced users to take the reigns and customize their workflows. Some object to operational AI because they believe it automates data scientists out of the process, but this is a misunderstanding of what operational AI aims to achieve.
Operational AI prescribes a worldview where production processes should largely be automated and predictable. If we can return to our comparison with software engineering, this is akin to how the CI/CD systems automate most of the compiling, testing, and deployment of production code, allowing engineers to focus almost all of their efforts on developing new code (and, of course, fixing the occasional failing integration test). Software engineers do not simply create code from pre-written blocks of existing code, and likewise, an operational AI system does not solely rely on pre-baked features and models. A production ML workflow will fetch data from a feature store, build models on the latest data, run analysis on the data and model, and deploy models according to a predetermined policy. Everything that happens at runtime should be already determined by the declarative nature of the system, but it’s also expected that data scientists will be able to input their own customizations into this process. For example – advanced data scientists may be adept at creating their own models. These models can be registered with the system and declared as part of the workflow when the production process is defined.
The extensible nature of an operational system is crucial for building users’ trust in the system. This provides a framework for which users can package up their development work and make it easily accessible to users in the system. The data scientist team no longer has to worry about the details of deploying projects that leverage their work, as the system handles all the details.
Additionally, operational AI makes it easy to use the work of a data scientist without having to understand all the details about how it’s implemented. This is excellent for organizations who are trying to get more domain expertise into the ML workflow, as the declarative nature of the system allows anyone with access to and knowledge of the data to start building ML use cases. No ML expertise is required, nor is knowledge of coding or ML frameworks. Users can quickly iterate on features and plug them into any number of models and see the results. Data scientists can also customize other parts of the pipeline, like feature transforms, model analysis, explainability, etc. to give users a better idea of how well their use is doing, as well as giving them a quick and easy way to evaluate models when they are called in as the expert. Indeed, this is a system that exactly allows other data professionals, like data engineers and data analysts to execute ML workflows without having to adopt the ML tooling. We’ve also avoided messy integrations and pipeline jungles, and can easily and simply deploy ML use cases into production. This is what bridging the gap looks like!
Go Forth and Prosper!
With a stellar operational AI system in place, the only thing left to do is execute use cases en masse. Remember that the ultimate goal of any data workflow is to provide the business with valuable insights that allow them to make smart decisions, take definitive actions, and prioritize use cases accordingly. Work closely with business stakeholders to learn what use cases are needed most, what the ROI of a use case is, and what acceptable results look like.
For each use case, it is of utmost importance to understand what is important to the business and how they will use it. For example, it could be the case that the business doesn’t care so much about the actual churn predictions from a churn model, but merely wants a ranked list of customers to target in order to optimize outreach and marketing. The former would likely best serve the business by syncing the data into the company’s CRM via a reverse ETL process, whereas the latter may be best served simply as a report that surfaces in a BI tool.
Get early buy-in around use case ROI and acceptable model performance. Data scientists tend to be perfectionists and it is often a lot of work to squeeze out those last few points of performance in a model. But how important are those last few points? Maybe it’s rather inconsequential to the business and it would be better to spend that time on developing brand new use cases. We’ll never know if we don’t ask, and we should strive to set business goals and expectations up front so there is no ambiguity pertaining to the value of a use case.
Lastly, aim to fail fast on all use cases. An operational system makes it amazingly easy to iterate on new ideas. Many use cases reuse data already contained in the feature store, custom models can be applied via declaration, and we should be able to tell if a use case is worth further investigation with very minimal effort and time committed. The more data fed into the system and the more use cases tackled, the easier this will be to see. Operational systems often get the most uplift by combing through data sources and finding new features to add to new or existing models rather than trying to code new models, but it is possible to do all of the above when needed.
Bridging the Gap Between Analytics and AI in the modern data stack Ecosystem
Putting all the above together within the modern data stack is actually not difficult. There are several things aligning within the modern data stack that make this straightforward.
- Many modern data stack tools provide a declarative interface.
- Many modern data stack tools follow software engineering best practices and have great gitOps workflows that easily enable production workflows via CI/CD or similar.
- Vendors have put a lot of thought and effort into streamlining integrations so you don’t have to.
The integration between dbt and Continual means you can start building and operationalizing ML workflows directly within a dbt project, and this positions dbt as being perhaps the most powerful feature engineering tool on the market. When leveraging dbt and Continual, the above steps above are really just extensions of what is already happening in dbt. Continual provides a closed-loop system that can operate out of an existing dbt project and allows advanced users to extend Continual’s functionality when needed.
By learning from past inefficiencies in enterprise data processes, modern data stack adopters are building data teams to maximize output and business impact. This drive for results necessitates a unified data process that allows all parts of the data team to seamlessly collaborate and contribute. If modern data teams refuse to shed the convoluted workflows of the past, they are undoubtedly chaining themselves to Sisyphus’ boulder.
Similar Journal