
Jump To

Active metadata is like hot gossip. Here’s why.
Just like data mesh or the metrics layer, active metadata is the latest hot topic in the data world. As with every other new concept that gains popularity in the data stack, there’s been a sudden explosion of vendors rebranding to “active metadata”, ads following you everywhere, and… confusion.
With everyone talking about active metadata, it must be pretty easy to understand, right?
Apparently not! I’ve been talking about active metadata for over a year now, but I still see questions like these all the time.
Active metadata can sound a bit scary, but it doesn’t have to be. It is a must-have tool in the modern data toolbox, so if you’re still wondering what it means, this article is for you.
I’ve broken down the ideas behind active metadata with as little jargon as possible. Keep reading to learn what active metadata is, what it looks like, how you can actually use it, how it fits into the modern data stack, and why it even matters.
What is active metadata?
I could start dropping some jargon here, but then both you and I will be asleep in seconds. So let’s jump into an analogy instead.
Imagine that you got your hands on the juiciest piece of tech gossip — Apple is expanding into recreational marijuana to literally help people “think different”.
There’s no way you’re going to keep something this exciting a secret. The world has to know. So you post it on your blog, blogspot.applefansunite.com. All done, right?
Just like a car in the Hyperloop tunnel, we all know that’s not going anywhere. You can’t just put the story somewhere and hope people will find it. You have to actually deliver it into people’s hands.
You sharpen your PR chops, blast the news to tech reporters and news sites, and lo and behold it’s everywhere in no time. It’s already been mummified, and your grandfather just asked why apple farmers are talking about this Molly girl on your group chat.
Metadata is like this information. If it sits passively in its own little world, with no one seeing or sharing it, does it even matter? But if it actively moves to the places where people already are, it becomes part of and adds context to a larger conversation.
What is the difference between active and passive metadata?
Passive metadata is the standard way of aggregating and storing metadata into a static data catalog. This usually covers basic technical metadata — schemas, data types, models, etc.
Think of passive metadata as putting out information on a personal blog. Every so often, it’ll get picked up and go viral on Hacker News. But most of the time it’s just going to sit unseen and unused, even when people actually need to know it.
Active metadata makes it possible for metadata to flow effortlessly and quickly across the entire data stack, embedding enriched context and information in every tool in the data stack. It is usually more complex than passive metadata, covering operational, business, and social metadata along with basic technical information.
Think of active metadata as a viral story. It shows up everywhere you already live in what seems like seconds. It’s immediately cross-checked against and combined with other information, bringing together a network of related context into a larger trend or story. And it sparks conversations, making everyone more knowledgable and informed in the end.

Why does active metadata matter?
To put it simply, no one wants to go to another website to “browse the metadata”.
As we embraced the internet and data exploded in the early aughts, companies realized they needed to manage all their new data.
We entered a golden age of metadata management. New companies like Informatica, Collibra, and Alation were created, and they hyped the importance of data catalogs. People needed a way to sort through all their options, so we got reports like Gartner’s Magic Quadrant for Metadata Management. Billion-dollar companies emerged, and companies spent hundreds of millions of dollars on metadata management.
Yet just last year, Gartner released their Market Guide for Active Metadata and declared that “Traditional metadata practices are insufficient…”
That’s because passive data catalogs solve the “too many tools” problem by adding… another tool. They aggregate metadata from different parts of the data stack, and it stagnates there. User adoption suffers, and these exciting tools turn into expensive shelfware.
Active metadata sends metadata back into every tool in the data stack, giving the humans of data context wherever and whenever they need it — inside the BI tool as they wonder what a metric actually means, inside Slack when someone sends the link to a data asset, inside the query editor as try to find the right column, and inside Jira as they create tickets for data engineers or analysts.
How does active metadata fit into the modern data stack?
Active metadata functions as a layer on top of the modern data stack.
It leverages open APIs to connect all the tools in your data stack and ferry metadata back and forth in a two-way stream. This is what allows active metadata to bring context, say, from Snowflake into Looker, Looker into Slack, Slack into Jira, and Jira back into Snowflake.
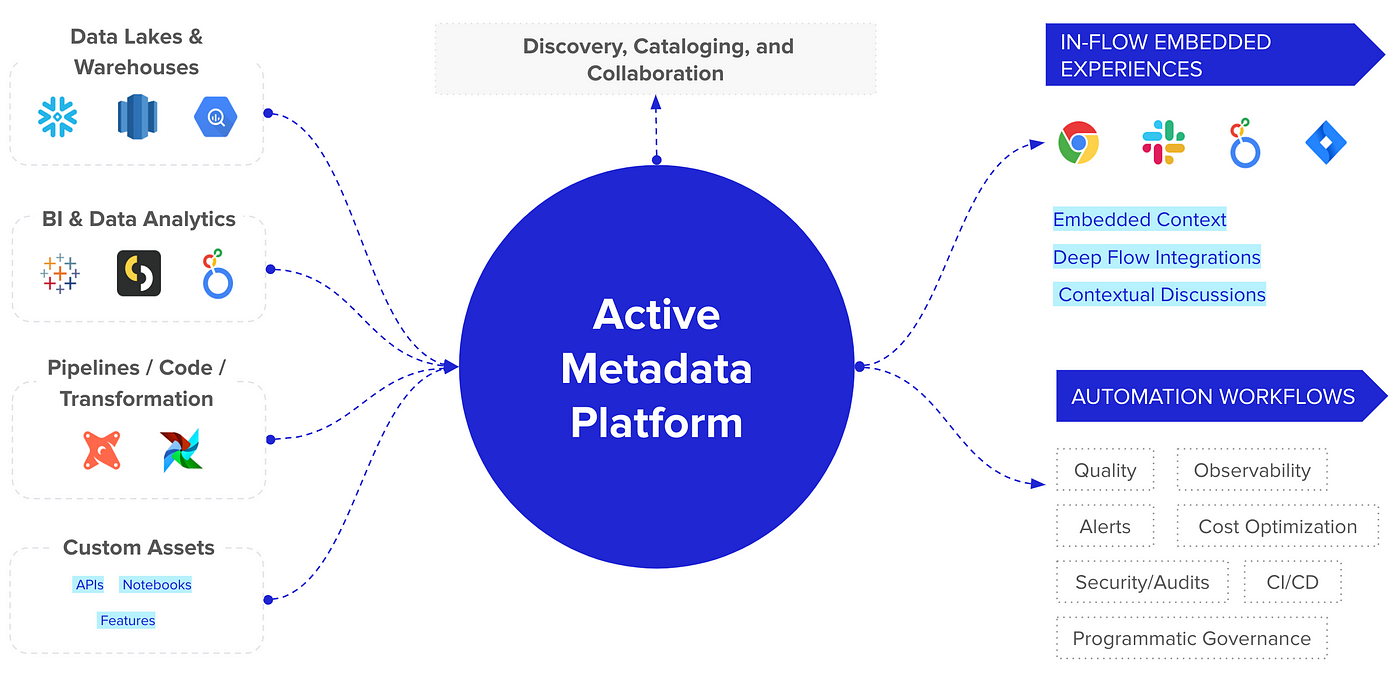
4 characteristics of active metadata
According to Gartner’s new Market Guide for Active Metadata, active metadata is an always-on, intelligence-driven, action-oriented, API-driven system, the opposite of its passive, static predecessor.
This can be broken down into the four key characteristics of active metadata.
- Always on: Active metadata is always on. Rather than waiting for people to manually enter or parse metadata, this means continually collecting metadata at every stage of the modern data stack — logs, query history, usage statistics, and more.
- Intelligent: Active metadata isn’t just about collecting metadata. It’s about constantly processing metadata to connect the dots and create intelligence from it. This means that with active metadata, the system will only get smarter over time as people use it more and it observes more metadata.
- Action-oriented: Active metadata doesn’t just stop at intelligence. It should drive action by curating recommendations, generating alerts, and making it easier for people to make decisions — or even automatically making decisions without human intervention, like stopping downstream pipelines when data quality issues are detected.
- Open by default: Active metadata platforms use APIs to hook into every piece of the modern data stack. This makes magical user experiences possible by saving data practitioners from the endless tool- and context-switching. This is called embedded collaboration, which is when work happens where you are with the least amount of effort.
5 use cases of active metadata
There are dozens, if not hundreds, of use cases of active metadata. (Enough for several articles of their own — coming soon!) Let’s go through a few of my favorites.
- Purge stale or unused assets: Use active metadata to periodically calculate when each asset (e.g. a data table, dashboard, etc) was last used and/or how many people used it. If it was used within the last 30 days, great! If an asset hasn’t been used in the last 60 days, automatically archive it. If no one has touched it in the last 90 or 120 days, purge it entirely.
- Allocate compute resources dynamically: Imagine that 90% of users log in to a BI tool during the last week of a financial quarter. Active metadata can be used to automatically scale up compute resources just before that week and scale them down again afterward.
- Enrich user experience in BI tools: Instead of switching between a BI tool and data catalog, use active metadata to bring context into dashboards. Relevant metadata (like business terms, descriptions, owners, and lineage) can be pushed into the BI tool. Then when someone is looking at each table, they can understand who owns it, where the data came from, etc. This information could even be used as labels in auto-generated reports.
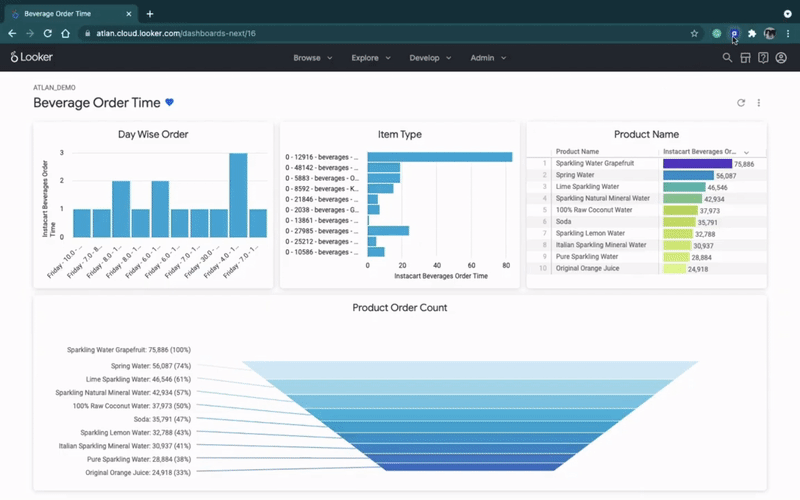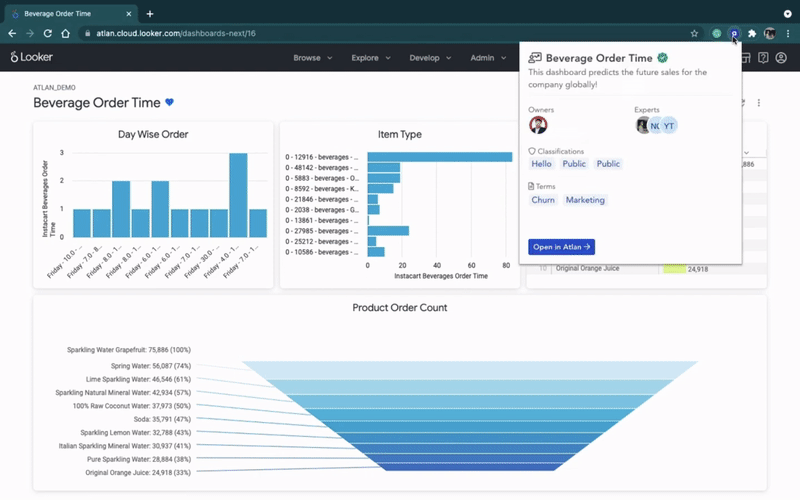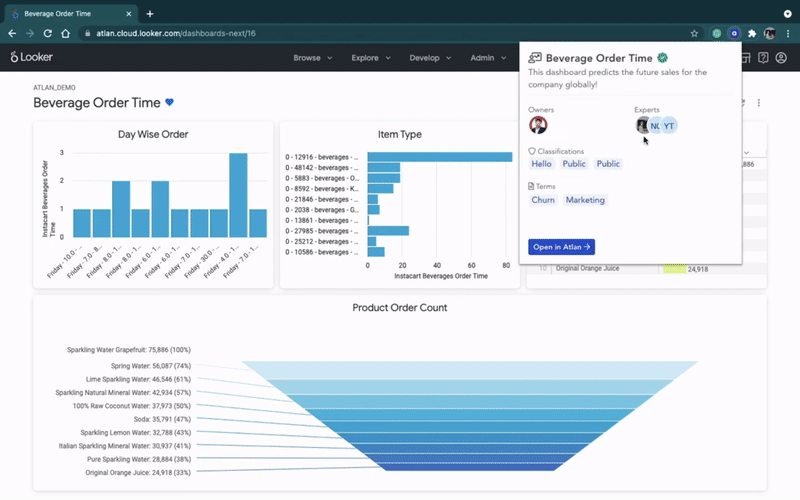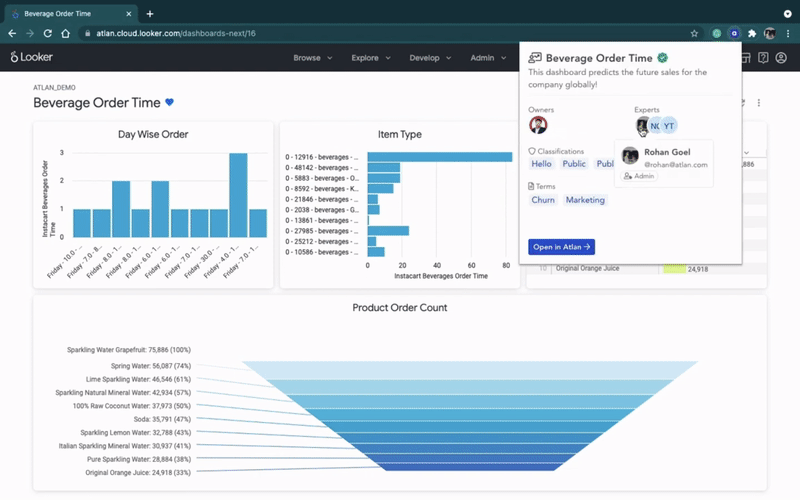
- Identify popular assets: Use active metadata to create a custom relevance score for each asset. This can be based on usage information from places like query logs, lineage, and BI dashboards. Then the most popular, relevant assets should be surfaced more frequently in search and checked more frequently for data quality issues.
- Notify downstream consumers: It’s awful if the CEO ends up seeing a broken dashboard before the data team. Active metadata can be used to check for issues when a data store changes and notify downstream data users about potential issues. For example, when a data store is crawled, the new metadata would be compared against previous metadata. If there are any potential breaking changes (e.g. the addition or removal of a column), lineage could be used to find who owns this data store and notify them in Slack, Jira, email, etc.
The future of active metadata
As metadata becomes big data and big data becomes a behemoth, active metadata isn’t just a wonderful dream. It’s a necessity — the only way to understand today’s data.
Managing, processing, and analyzing metadata is the new normal for modern data teams. Doing this passively and manually, though, isn’t possible. That’s why it’s been so exciting to see active metadata take shape in the last year and become the de facto standard for what people expect out of modern metadata.
All of these use cases — like auto-tuned pipelines, automated data quality alerts, and continuously validated calculations — would have sounded wildly impossible just a few years ago. Today, they’re actually in reach. I couldn’t be more excited to see the intelligent data dream become a reality as active metadata continues to evolve in the coming years.
Similar Journal












