10 tips for building an advanced data platform


Jump To

Hi from Data Management team at Eureka 👋
Last year I wrote about our migration to the new modern data platform Metis. In November 2022, we officially started using Metis in production data workflows. This was a long journey with a lot of effort and many achievements, we learned a lot during the migration!
This time I decided to focus on a more practical aspect of data platforms with tips for data platform engineers or managers. Here is a compilation of tips that we either implemented from the start, learned along the way or currently having in works for Metis.
Note: in this article, by ‘users’ I mean users of an internal data platform, most likely they are company employees. By ‘customers’ I mean users of a product or a service that the company is providing.
List of tips covered
- Build your data platform as a product
- Use asset-based approach to data instead of pipelines
- Manage your data platform infrastructure as code
- Set moderately strict limits on data platform and relax them when needed
- Partition and cluster tables
- Consider when to use a SaaS, an open-source solution, or build your own
- Create an internal data catalog
- Create a monitoring center for the data platform
- Keep things simple for data platform users
- Periodically check your data inventory and do a clean-up
Tip #1: Build your data platform as a product
This, in my opinion, is the most impactful thing you can do for your data platform users.
When a company builds an application or a service, it builds a product. Such product has:
- Customers
- Technical infrastructure
- Product planning to define what to build
- Marketing efforts to get customers
- Customer support to handle problems and incidents
Now, what if we apply the same way of thinking to an internal data platform?
- Customers: every data platform has users, who are most likely company employees
- Technical infrastructure: you need resources and technologies to create a data platform
- Product planning: building a data platform requires a lot of planning like choice of tools, functionality, data warehouse design etc.
- Marketing: you need to promote your data platform’s functionality to on-board new users and explain added functionality to existing users
- Customer support: any data platform team needs to respond to users’ requests and handle data-related incidents
If we can apply product characteristics to a data platform, then why don’t we build data platform as a product instead of creating a set of connected technologies that make sense only to data platform teams?
Consider data platform as an internal product, its target market as your company and target audience as employees. Create name and logo for the data platform and advertise it internally under its name instead of a generic “data platform” term or the name of your data warehousing solution. Get all your data tools under this name and refer to them as a functionality.
For example, if your data platform product is named “Helios” (Greek word for “sun”), then your Tableau Server is the data visualization functionality of Helios. From the perspective of a user, they will be using a “Helios dashboard that aggregates Helios data”. It’s much easier for everyone to remember one product name and get the idea of its functionality, rather than trying to figure out what different data technologies do and how they are interconnected. When using Google Spreadsheets, you generally don’t think about what modules, resources and APIs it consists of, right?
I also recommend creating a landing page for your data platform product. A simple internal webpage with data platform’s name, logo and a list of links to functional components is sufficient. For better access and visibility, assign it a simple internal URL address (using the same Helios example from above, something like internal-domain.com/helios or helios.internal-domain.com would look great). Create a user manual for your data platform product and put the link on the landing page.
The most important thing here is having a single entry point to all functionality of your data platform. No need to research countless internal wiki articles and ask teammates for the information — anyone can start using the data platform just by visiting a link.
At Eureka, we used this method to build a new modern data platform product that we named Metis.

Thanks to the creation of Metis, we now have a simple, fast, resilient, reliable, cost-efficient and easy-to-use internal data platform. Our data teams actively use the name “Metis” instead of “data platform” or “BigQuery” or “GCP”, and many employees who do not directly work with the data platform have at least heard about Metis, its functionality and role in the company.
Check out last year’s article for a (slightly technologically outdated) overview of Metis!
Tip #2: Use asset-based approach to data instead of pipelines
In comparison with tip #1, this, in my opinion, is the most impactful thing you can do for yourself as a data platform engineer or manager.
Traditionally, when data engineers create data pipelines, they write instructions (code) that declare what operations to execute. Imagine a daily data pipeline in Airflow or cron-scheduled shell script that gets data from source A, transforms data into file B, uploads file data to table C, aggregates it into a table D and runs a refresh via API on server E. We have a clearly defined process consisting of 5 operations and expected output of this process.
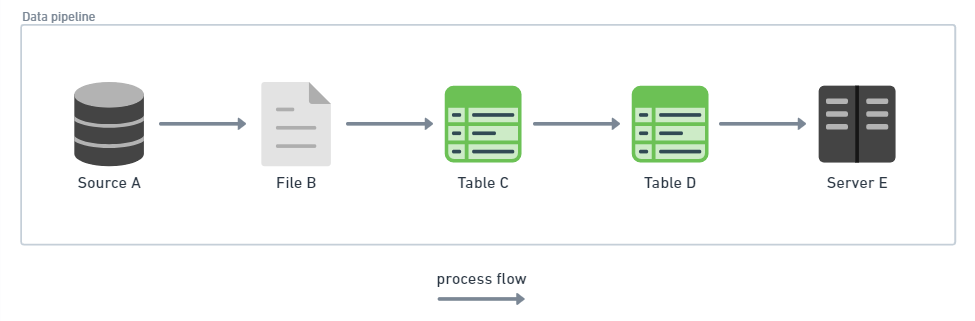
- What if this pipeline fails on step D? We need to fix the process and re-run it from the start.
- What if one pipeline depends on an output from the other? Now we need to create a mechanism that connects those two pipelines. And if one of data outputs in the second pipeline doesn’t actually depend on the result of the first pipeline, then we have an unnecessary blocker when the first pipeline fails.
As many data engineers know, dealing with such pipelines is a cumbersome process that costs a lot of time, effort and makes data engineering unnecessarily hard.
What if instead we put our focus not on what operations to execute, but what we want to exist? What if we embrace the declarative approach to data and start declaring data assets instead of pipelines?
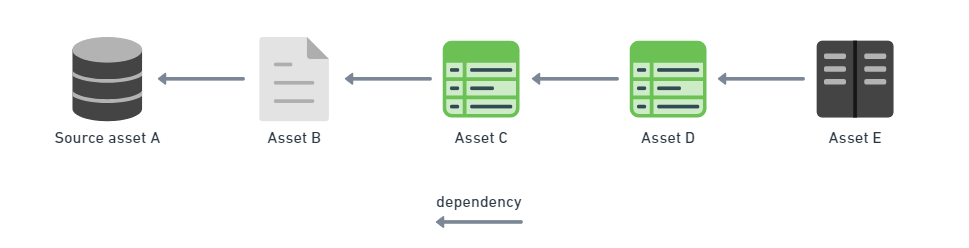
Much like Terraform’s approach to infrastructure resources (discussed in tip #3), we can just define what data asset (table in a data warehouse, file, ML model etc) we want to create, how to create it and what dependencies on other data assets it has. This gives each data asset its own entity so we can work with them independently. When we want to materialize several data assets at once, we just need to specify which ones to materialize without the need to worry about their relationships. Since dependencies are already defined, each data asset knows from what other data assets to pull the data for processing, or to what data assets push processed data.
Moreover, declared dependencies enable automatic data lineage and operational data catalog without any extra effort. Operational data catalog is the one that the data platform team uses to work with data assets and their lifecycle.
dbt is one such popular tool that enabled asset-based approach to the data warehouse. Instead of creating data pipelines, you just write a SELECT SQL query for the table you want to create, give this table (model) a name, create optional YAML configuration and specify what other tables it depends on. Then just schedule your jobs and let dbt do the rest. Simple to create, maintain, and you get the data lineage out of the box.
But I believe the real breakthrough in this field is Dagster with its Software-Defined Assets approach. The general idea is similar to the one of dbt, but instead can be applied to any data asset. Whether it’s a table in a database, a data extract from an API, a file in a cloud storage bucket or a machine learning model — you just need to define it in Python code and specify dependencies. Create a job with a selection of assets you want to materialize and add a schedule or a sensor. Dagster will automatically materialize selected assets while preserving order of dependencies. Moreover, you can import data assets from other tools, including dbt!
Dagster and dbt are probably two most powerful tools that we have implemented in Metis. They replaced complex and fragile Airflow pipelines, custom shell scripts and a couple of detached data tools. We got clear observability over our data assets thanks to the automated operational data catalog, our daily data operations got much easier, and we visibly increased the reliability of our new data platform.
I really recommend spending some time studying Dagster and understanding asset-based approach to data to see how it can improve your current data workflows. It was such a huge positive upgrade for us so that it’s hard to imagine going back to previous ways of doing data engineering. There are detailed explanations of all features in docs and blog posts such as this one.
Tip #3: Manage your data platform infrastructure as code
If your tech stack allows it, it pays off to define data platform resources and automate their lifecycle in an Infrastructure as Code (IaC) tool, such as Terraform. The amount of clarity, simplicity and peace of mind this approach brings is difficult to overestimate.
It’s easy to start with the IaC approach to data platform resources. Spend some time studying the tool, configure CI pipeline that runs the tool and import existing resources. Next time you need to add, modify or delete something in your data platform, just modify the code as needed, create a Pull Request, merge approved changes and confirm that the deployment was a success.
Note that as with everything, balance is important. For example, most likely it won’t make sense to define a resource for absolutely every table that you want to create in your data warehouse. Instead, consider letting other data tools (such as dbt and Dagster) to create table resources on the fly. Going too granular will add a huge operational overhead, and not putting all main resources in code makes the data platform less reliable, messier and prone to incidents. But if done right, such IaC repository becomes both your data platform’s technical inventory and management plane.
In case of Metis, we went with defining all technical infrastructure resources down to a dataset level and access controls with Terraform and putting BigQuery table definitions in our dbt repository. This creates a simple abstraction: when we need to add infrastructure or configure access controls — we do it in the Terraform repository. When we need to add data to Metis, then it’s either dbt repository (for SQL-generated data) or Dagster repository (for non-SQL-generated data).
Tip #4: Set moderately strict limits on data platform and relax them when needed
When you’re in charge of a data platform, you’re also in charge of data security, data access and data processing costs, among other things. To keep the data safe and costs down, make sure to set:
- Access controls on who and how can access what data
- Cost controls on who can query and use how much data
As always, balance is important. Restricting your internal users too much will halt a lot of work and giving them too much freedom to use the data platform creates security and financial risks.
I recommend going with a moderately strict limits first and create a simple way to relax those limits when needed. Changing current restrictions might need approvals from upper management or other stakeholders, so consider how to make that communication simpler as well.
Also consider how to apply the controls above. For example, you can control access to data on a data warehouse, dataset, table and/or column level. Consider which option makes the most sense for your organization and implement accordingly. In our case, we found that controlling access on a dataset level while protecting certain columns with column-based policy tags works well as a balanced solution.
For cost controls, having a moderate total daily data scan limit and making sure users know about it provides a good starting ground. Separate on-demand workloads into its own quota pool and set the limit accordingly. On-demand workloads in a data platform are usually not critical, so the quota will protect your data platform budget. And when a critical use-case to scan a lot of data comes up, you can always temporarily increase the quota limit.
When implemented right, your security and financial teams will be very grateful to you, and your data operations will be easier, safer and cheaper.
Tip #5: Partition and cluster tables
This tip is written based on BigQuery, but I believe other data warehouses have the same or similar functionality.
Partitioning and clustering of tables is the one method that is easy to implement and gives you huge performance and cost saving benefits right away. When you have a lot of data in a table, there is no reason not to use either or both.
Partitioning
Partitioning allows you to logically split the data into different partitions based on a date or a number. By partitioning a table by day using a DATETIME column (for example, created_at), the data for, let’s say, December 18, 2022 (2022–12–18) will automatically land in its own partition. Then, when you want to retrieve the data for this day and specify the condition WHERE DATE(created_at) = DATE("2022-12-18") , the SQL engine knows that it needs to scan only the “2022–12–18” partition for data. Since only one partition of the whole table needs to be scanned, the query becomes much faster and much cheaper.
Same goes for uploading data into a table. No more time-consuming and costly UPDATE or MERGE operations — when you need to rewrite data for a specific date, just delete the partition and re-upload the data!
If you have data in Cloud Storage, you can also similarly partition the data using Hive partitioning layout.
You can also partition existing tables by temporarily stopping data ingestion into a table, moving all data into a newly created partitioned table, deleting the old table, and renaming the new table to the previous name.
Clustering
What if you have a lot of data in a single partition or a big table without a column to partition on, but still want to improve performance and reduce costs? Clustering allows you to further split data into clusters. Let’s say you have a table with purchase transactions per store in different cities, and your most common use case is to calculate total transactions per specific city per store. By clustering the table by city and store_name columns you automatically optimized all queries with WHERE city = X AND store_name = Y conditions, since now they scan only specific clusters of the table. Combine that with partitioning and now you have very efficient queries without rewriting any SQL!
Before Metis, we only had a manual partitioning method and no clustering configuration on our tables. By partitioning and clustering large and heavily used tables we achieved huge boost to performance and huge cost savings. In one case, we managed to bring down the cost of a specific use-case by 99.8% and reduced query runtime by 75% !
That said, there is no need to partition and cluster absolutely every table. If you have a table with 1000 rows of data that you don’t expect to grow, then you won’t notice any benefits from partitioning or clustering. Identify the tables which will give you most gains and start from them.
Tip #6: Consider when to use a SaaS, an open-source solution or build your own
There is no tool that fits all use-cases. Whether it’s a data warehouse solution, ETL or visualization tool, the choice of which one to use will depend on the goals, needs and current situation in your organization and data department.
Save your team and company from future troubles by thoroughly evaluating your situation and available tools in advance.
- List your use-cases and requirements
- Summarize advantages and disadvantages of each tool
- Evaluate compatibility with your data and tech stack, consider usability
- Narrow the list down to possible matches
- Subscribe to the trial period of a SaaS service or install an open-source solution on a test machine, and thoroughly evaluate each tool on use-cases that are as close to real data volume and velocity as possible
Most likely there will be a need to make a trade-off — consider the one that has the least impact. For example, existing ETL tools such as Fivetran or Airbyte might easily handle many various simple batch data sync workflows, but they might not be able to process huge amounts of data in short time fast enough. Research if there is a solution that can handle both use-cases, evaluate if it makes sense to add a custom solution, or go with a completely different option.
This is the part where it’s easy to go wrong and then suffer from the consequences of that choice when the tool already has too many dependencies in your stack. A well thought out choice from the start can save you from a costly and lengthy migration later.
Tip #7: Create an internal data catalog
Operational data catalog mentioned in tip #2 is very useful for the data platform team, but it’s not suitable to be shared with users. After all, it’s probably not a good idea to give the keys to managing all data assets to users.
Instead, it’s a good idea to create a simple data catalog that focuses on describing the data you have and enables data self-discovery for your users. Having a centralized data catalog will greatly help in reducing the amount of “Where is X data?” questions, and will give a complete visual picture of all existing data in your company, thanks to the data lineage and descriptions of your data assets.
What is the difference between the two types of data catalogs?
- Operational data catalog — describes the desired state of data assets based on code definitions.
- User-facing data catalog — describes the actual state of data assets based on the scan of your current data inventory.
Getting started with a user-facing data catalog is a straightforward process:
- Research available data cataloging solutions. There are plenty of options — find the one which fits your goals, requirements and tech stack the best.
- Install or subscribe to the data catalog of your choice, and connect it to all your sources and data assets to ingest metadata about them.
- Create a schedule or triggers to periodically scan and update the contents of the data catalog.
Don’t forget that this is an active catalog — it needs to be maintained, cleaned and categorized periodically. It might look like an additional operational burden on the data team (in some cases requiring putting on a completely new ‘data steward’ hat), but in reality it can greatly help to reduce operational overhead and the number of data related questions. It can also improve overall data operations and knowledge about the state of data inside the company.
Tip #8: Create a monitoring center for the data platform
Do you have a screen that you can open and understand the current health of the data platform just at a glance? It’s common for infrastructure teams to have dashboards for checking an application’s or service’s infrastructure health, so it should also be common to do the same for data infrastructure.
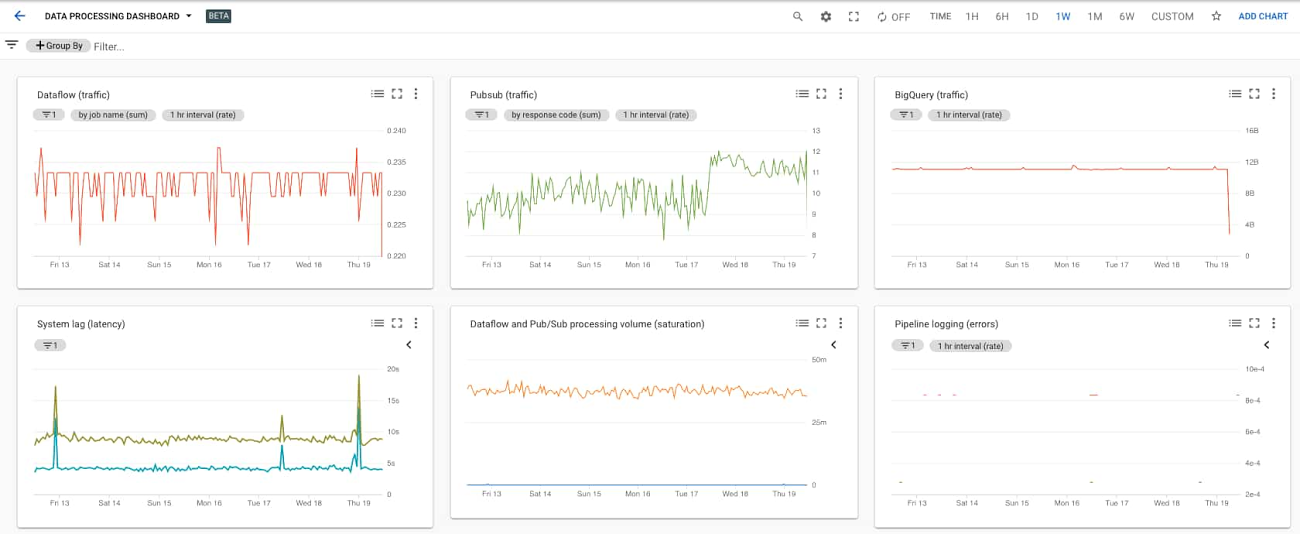
Creating a unified monitoring center for a data platform doesn’t take much time, but provides great observability, makes data operations much easier and helps prevent or recover faster from incidents.
- Spend a couple of days to learn a monitoring solution of your choice (we use integrated Google Cloud Monitoring)
- Spend a couple more days creating dashboards with metrics for your data platform resources like pipelines and virtual machines. Data ingestion rate, CPU\RAM usage rate for your Tableau Server VMs, data insert errors etc.
- Add thresholds and alerts that will automatically notify you when something is wrong
This can be done either manually or specified in code (with tools like Terraform). Now you not only have automated notifications when something went wrong but can always get current status (and peace of mind) just by opening the monitoring center’s dashboard.
Tip #9: Keep things simple for data platform users
Data platforms are complex structures. The bigger the company the more so. Many stakeholders across different teams and departments directly or indirectly use internal data platform. Make this complex structure as easy for them to use as possible!
There are many ways to simplify a data platform and it largely depends on the company, including current tools, methods and approaches. The secret is to think from the perspective of your internal users — same way how product’s UX is built from the perspective of a customer. Some ideas:
- Have a clear, defined, easy to understand structure for organizing data. For example, what dataset is used for what data or purpose. Add necessary descriptions and/or simple documentation so users can understand what data is located where.
- Create naming conventions for data assets. Often mentioned example is adding
dim_orfact_prefixes to tables if you are using star schema design. Do the same for code, for example having all source assets to follow a naming pattern like<source>_<region>_<table_name>or similar. - Less available tables often mean more productivity. Before Metis we had a lot of tables in a format like
events_20221218that were created with a date suffix per each day. Imagine how many tables you need to go through when you have a handful of such tables and a couple of years of data, each with a suffix!
We moved to single partitioned tables, i.e.,eventstable partitioned by day. Much easier for users to use the data from just one table, and for the data management team to manage data assets. - Make it easy for users to contribute to the data platform. For example, before Metis, when our data analysts needed to add a new table to BigQuery or modify a current one, they had to modify an often complex data pipeline spanning several data tools, each requiring an understanding of how it works.
Now in Metis, they just need to fill in a table configuration YAML template, create a file with a SQL query, and put both files in a internal dbt git repository. Everything else is automated. The only knowledge required is basic dbt concepts and commands, and BigQuery SQL. - Use visual explanations where possible. Create simple diagrams with a diagraming tool. This saves a lot of time for both you (explanations are faster, less questions) and data platform users (understanding is faster).
Each company is different, so get to know your internal users well and think about how you can make their data operations easier!
Tip #10: Check your data inventory periodically and clean it up
This is a universal tip for any process where you manage a collection of something — data assets in a data platform, personal notes, task lists, or just items in your fridge. Check the inventory of things that you have and remove the ones that are no longer needed. It’s normal to throw away an expired can of beans found in a fridge — why not do the same and delete all those test_<something> tables in the data warehouse that you created a couple of years ago and which are no longer needed?
As a data manager, create a list of data assets that don’t look like being used, and schedule periodical sessions with data platform users (or just ask them on Slack\Teams) to check whether those assets are needed or can be deleted.
To keep your development environment clean and tidy, another useful approach is to attach a Time-To-Live (TTL) configuration to personal datasets or other resources to automatically delete stale tables. Just make sure that your data platform users know about it!
I hope the tips above can help you create a more efficient, simpler and better data platform. They worked for us, and I believe can work for many other companies. However, remember that each situation is different, so consider your current state of the data platform and the situation in the company before implementing these tips.
Bonus tip: No matter how technically good your data platform is, in the end, communication is the key to success. You must advertise the data platform and explain the benefits of using it to get the buy-in from users and make it a successful internal product. Good luck!
Similar Journal













